
After learning that GOV.UK’s hosting platform PaaS is being decommissioned, the Energy Performance of Buildings (EPB) Register team decided to migrate all our hosting to AWS.
Our database currently holds over 30 million energy performance certificates (EPCs) in the form of XML documents. We receive about 7,000 new EPCs per day on average – these are lodged by accredited energy assessors, using approved third-party software. Our GOV.UK sites, Find an energy certificate and Get a new energy certificate, receive 75 to 100 requests per second on average.
Given these high traffic numbers, one of our biggest challenges was how to move our production data with minimal service downtime.
The challenge: migrating with minimal downtime
Our database runs on PostgreSQL, which provides tooling to back up and restore data. We integrated these tools into the migration of our pre-production databases.
However, the size of our production database (over 800GB) meant it took over 12 hours to back up data from PaaS and then another 12 to restore into Amazon’s Relational Database Service (RDS) using these tools.
During our production migration, we would have to take our database offline to ensure no new EPCs were lodged onto the PaaS database while it was being backed up. So we would need to take our service offline for over a day to complete our switch to AWS, and even longer if these long-running processes terminated for any reason and had to be re-run.
Postgres does have a built-in replication tool to solve this problem - an automated backup process in which data is repeatedly copied from a source database to another target database in real time.
However, for security reasons, this feature is not available within PaaS to ensure external agents and networks cannot access critical production databases.
Using a peering connection with PaaS
To be able to copy data between PaaS and AWS programmatically, we first had to solve the problem of getting our AWS virtual private cloud (VPC) to talk to our PaaS account.
PaaS created a VPC peering connection from our production environment that allowed inbound and outbound traffic on a specific IP address range and invited our VPC to connect to it. Using Terraform, we set up a private subnet within our VPC on the PaaS-specified address range, with corresponding network routing to PaaS via the peering connection.
Replicating our data
Initially, we planned to use the Postgres pg_logical extension to manage our data replication. However, we were not able to get this running successfully, and found scant documentation and no support. So, we decided to use AWS’s Database Migration Service (DMS) to manage our replication instead.
Given how mission-critical our data migration was, we felt it would be beneficial to use a well-established tool with good levels of support.
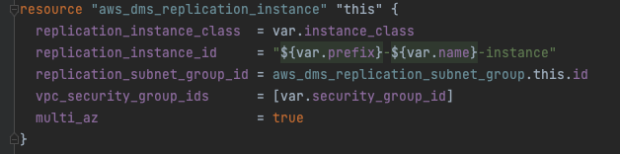
To set up DMS on our updated production VPC network, we first created a replication instance. This is a virtual machine, also known as an EC2 instance, large enough to deliver our data in replication from PaaS to AWS in reasonable time.
Security groups
To ensure the replication instance can read from the PaaS database and write to our target database in AWS, the instance was launched on the new private subnet. It needed a specific security group that allowed ingress/egress to the PaaS peering connection IP range. This security group was then added as a target in the AWS RDS security group, granting it the same permission.

Endpoints
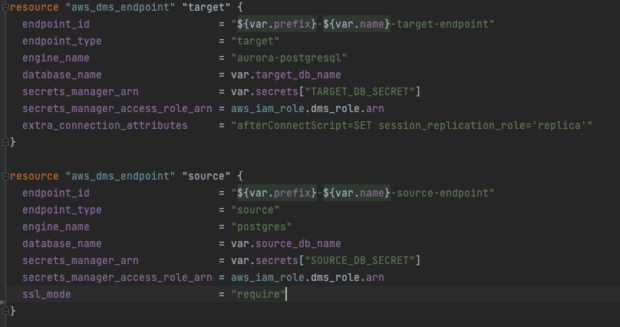
The replication instance requires an endpoint that provides connection, data store type and location information about your data store for the source (PaaS) and target (AWS RDS) databases.
We used AWS Secrets Manager to securely store the connection details for both databases within the same AWS account. PaaS provided us with specific superuser credentials. We Terraformed an endpoint for each database, which then read the values from AWS Secrets Manager. Once enabled, we used the AWS tool to test the endpoints, which confirmed all the network changes we made were working correctly and that the EC2 instance in AWS could connect to the database in PaaS.
Running replication tasks
We created a DMS task to run the replication between the source and target. This process runs the data replication on the DMS instance.
Here is an example of the creation of our task in Terraform.
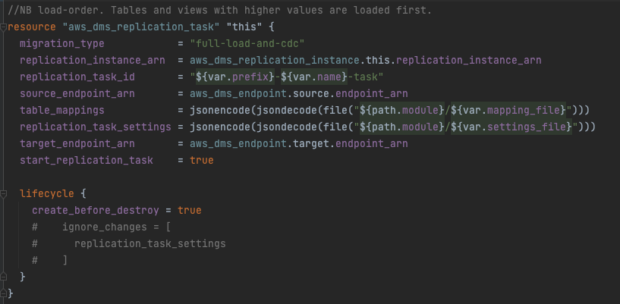
The task was configured using table_mappings and replication_task_settings which specify the type of replication and what tables to replicate in what order, with any data filtering required. We set the replication type as full-load-and-cdc, which bulk copies all the existing data while replicating any ongoing changes. This meant that as well as copying over our data, it would be kept up to date with updates until we switched over.
We set this up and then executed the task. DMS provides a tool that shows the status of the tables being replicated. All tables being copied show a status of Full load if the data transfer is in progress, Table completed or Table error.
Dealing with DMS table load errors
For our existing tasks, we had a few tables that were in error. One of these was the table used to store the XML documents which represent individual EPCs. The error was caused by the task’s default large object binary (LOB) size allocation being exceeded. Some EPCs are submitted with the binary data of images and documents embedded within the XML, giving us data points that are over 30MB. A maximum LOB value can be updated in the task’s settings.
It is also possible to disable the LOB max size completely, but AWS documentation says this can have a negative impact on performance. We found disabling it meant the task would take about 6 days to run the full load of that table before it could replicate ongoing changes. This gave us little headroom should something go wrong so close to our scheduled migration.
We analysed our data and found that only around 100,000 EPCs of a specific type potentially had oversized XML documents. We split the single task into three separate tasks to run in parallel, each with different values for the settings and table configurations. The first specified a small LOB size and included all the tables excluding the table that stores the XML. The second was set with a larger Max LOB used to transfer certificates that do not have large binaries. The third had no maximum LOB size set and a table filter to only import EPCs of the type that included LOBs. While the third task ran slowly, it only had to load a small fraction of the data and so completed a full load in only a few hours.
After checking the running tasks post full load, we could see new EPCs being lodged were sent from the source in PaaS to the target in just a few seconds.
For our tasks, we chose to replicate existing data and ongoing changes but not the database schema. Our reasoning being that we already had the schema in place by application of our code-first data migration. We therefore set the task to only replicate the data. The task’s default setting is:
"TargetTablePrepMode": "DROP_AND_CREATE"
On startup, this setting drops all the tables before a full load cycle begins. This seemed correct at first. But once we were in the process of migrating our service, we began to see table write errors from EPC lodgements. By checking the RDS error logs, we quickly realised the task had removed the schema while dropping the table – including the indices, foreign key constraints, default values and sequences – causing the table write errors. Luckily, at that point we were able to put our service back into read-only mode, which enables the public website to function while disabling any database writes from energy assessors. We then went through all the tables and re-added the foreign keys, sequences and default values that had been dropped. This solved the problem, so we could then put our service back into read and write mode.
Having DMS running on our production data meant we were able to migrate from PaaS to AWS without the additional downtime of having to back up and restore our data, without any loss of data and incurring only a few minutes of downtime for our service and our users.
Find out more
If you have any questions about this piece of migration work or the work of the team more generally, feel free to leave a comment.
- Read Amazon’s Database Migration Service documentation
- You can find the Terraform for our service infrastructure on this branch on GitHub
- Most of the DMS Terraform is in this folder on GitHub
Subscribe to our blog for the latest updates from the team or visit our job page if you're interested in working with us.

Leave a comment